Java系列(八)| Java集合
Java核心技术 集合类
Java 集合,也叫作容器,主要是由两大接口派生而来:一个是 Collection 接口,主要用于存放单一元素;另一个是 Map 接口,主要用于存放键值对。
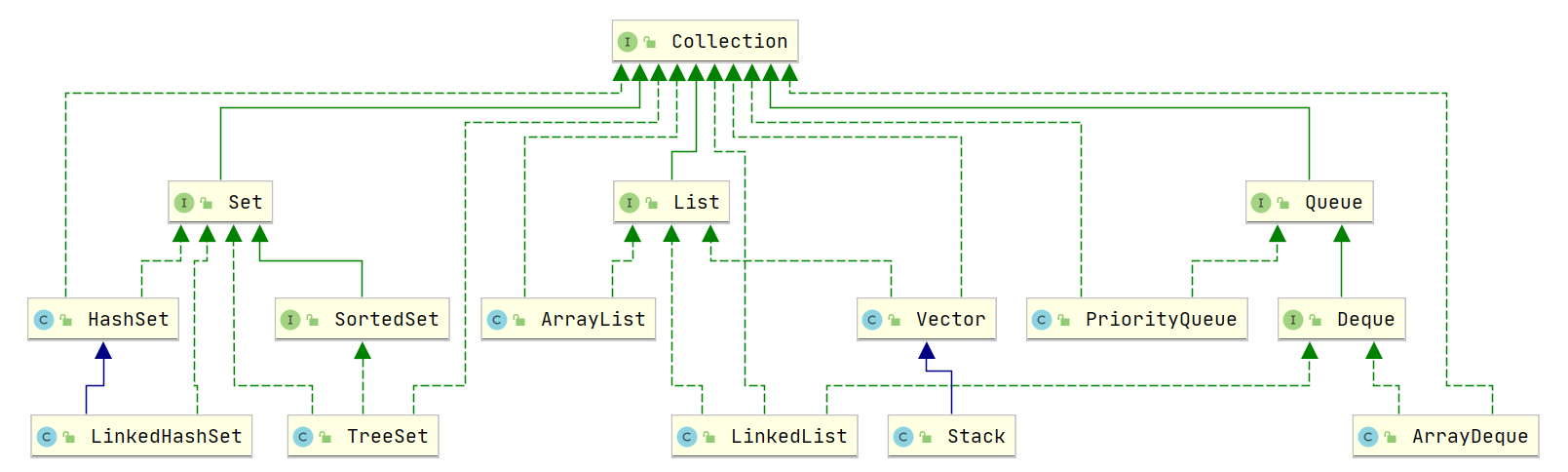
Collection 接口关系图
具体实现:List、Queue、Set,可以看下Collection关系图
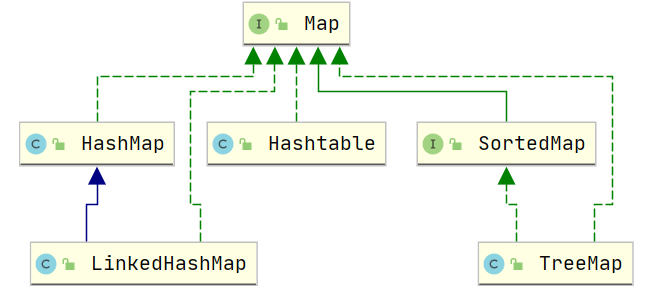
Map 键值对关系图
具体实现:Hashtable、LinkedHashMap、TreeMap,可以看下Map 关系图
1.List、Set、Queue、Map 区别
List:有序列表,可重复Set:无序列表,不可重复Queue:特性的排队顺序确定先后关系,存储元素是有序的,可重复Map:使用键值对(key-value)存储
2.List、Set、Map 常用集合有哪些?
List
- vector: 底层是数组,方法加了
synchronized来保证线程安全,所以效率较慢,使用ArrayList替代。 - ArrayList: 线程不安全,底层是数组,因为数组都是连续的地址,所以查询比较快。增删比较慢,增会生成一个新数组,把新增的元素和原有元素放到新数组中,删除会导致元素移动,所以增删速度较慢。
- LinkedList: 线程不安全,底层是链表,因为地址不是连续的,都是一个节点和一个节点相连,每次查询都得重头开始查询,所以查询慢,增删只是断裂某个节点对整体影响不大,所以增删速度较快。
Set
- HashSet: 底层是哈希表 (数组 + 链表或数组 + 红黑树),在链表长度大于 8 时转为红黑树,在红黑树节点小于 6 时转为链表。其实就是实现了
HashMap,值存入key,value是一个final修饰的对象。 - TreeSet: 底层是红黑树结构,就是 TreeMap 实现,可以实现有序的集合。String 和 Integer 可以根据值进行排序。如果是对象需要实现 Comparator 接口,重写 compareTo() 方法制定比较规则。
- LinkedHashSet: 实现了 HashSet,多一条链表来记录位置,所以是有序的。
Map<key,value> 双例结构
- TreeMap: 底层是红黑树,key 可以按顺序排列。
- HashMap: 底层是哈希表,可以很快的储存和检索,无序,大量迭代情况不佳。
- LinkedHashMap: 底层是哈希表 + 链表,有序,大量迭代情况佳。
3.ArrayList 的初始容量是多少?扩容机制是什么?扩容过程是怎样?
初始容量: 默认 10,也可以通过构造方法传入大小。
扩容机制: 原数组长度 + 原数组长度 / 2 (源码中是原数组右移一位,也就相当于除以 2)
注意:扩容后的 ArrayList 底层数组不是原来的数组。扩容过程: 因为 ArrayList 底层是数组,所以它的扩容机制和数组一样,首先新建一个新数组,长度是原数组的 1.5 倍,然后调用 Arrays.copyof() 复制原数组的值,然后赋值给新数组。
4. 什么是哈希表
根据关键码值 (Key value) 而直接进行访问的数据结构,在一个表中,通过 **H(key)计算出 key 在表中的位置,H(key)**就是哈希函数,表就是哈希表。
5. 什么是哈希冲突
不同的 key 通过哈希函数计算出相同的储存地址,这就是哈希冲突。
6. 解决哈希冲突
- 开放地址法:如果发生哈希冲突,就会以当前地址为基准,再去寻找计算另一个位置,直到不发生哈希冲突。 寻找的方法有:
- 线性探测 1,2,3,m
- 二次探测 1 的平方,-1 的平方,2 的平方,-2 的平方,k 的平方,-k 的平方,k<=m/2
- 随机探测 生成一个随机数,然后从随机地址 + 随机数 ++。
链地址法 :冲突的哈希值,连到到同一个链表上。
再哈希法 (再散列方法) :多个哈希函数,发生冲突,就在用另一个算计,直到没有冲突。
建立公共溢出区 :哈希表分成基本表和溢出表,与基本表发生冲突的都填入溢出表。
7.HashMap 的 hash() 算法,为什么不是 h=key.hashcode(), 而是 key.hashcode()^ (h>>>16)
得到哈希值然后右移 16 位,然后进行异或运算,这样使哈希值的低 16 位也具有了一部分高 16 位的特性,增加更多的变化性,减少了哈希冲突。
8. 为什么 HashMap 的初始容量和扩容都是 2 的次幂
因为计算元素存储的下标是 (n-1)& 哈希值,数组初始容量 -1,得到的二进制都是 1,这样可以减少哈希冲突,可以更好的均匀插入。
9.HashMap 如果指定了不是 2 的次幂的容量会发生什么?
会获得一个大于指定的初始值的最接近 2 的次幂的值作为初始容量。
10.HashMap 为什么线程不安全
- jdk1.7 中因为使用头插法,再扩容的时候,可能会造成闭环和数据丢失。
- jdk1.8 中使用尾插法,不会出现闭环和数据丢失,但是在多线程下,会发生数据覆盖。
- put 操作中,在 putVal 函数里,值的覆盖还有长度的覆盖。
11. 解决 Hashmap 的线程安全问题
(1) 使用 Hashtable 解决,在方法加同步关键字,所以效率低下,已经被弃用。
(2) 使用 Collections.synchronizedMap(new HashMap<>()), 不常用。
(3)ConcurrentHashMap(常用)
12.ConcurrentHashMap 的原理
- jdk1.7: 采用分段锁,是由
Segment(继承ReentrantLock:可重入锁,默认是 16,并发度是 16) 和HashEntry内部类组成,每一个Segment(锁) 对应 1 个HashEntry(key,value)数组,数组之间互不影响,实现了并发访问。 - jdk1.8: 抛弃分段锁,采用 CAS(乐观锁)+synchronized 实现更加细粒度的锁,【Node 数组 + 链表 + 红黑树】结构。只要锁住链表的头节点 (树的根节点),就不会影响其他数组的读写,提高了并发度。
13. 为什么用 synchronized 代替 ReentrantLock
①节省内存开销。ReentrantLock 基于 AQS 来获得同步支持,但不是每个节点都需要同步支持,只有链表头节点或树的根节点需要同步,所以使用 ReentrantLock 会带来很大的内存开销。
②获得 jvm 支持,可重入锁只是 api 级别,而 synchronized 是 jvm 直接支持的,能够在 jvm 运行时做出相应的优化。
③在 jdk1.6 之后,对 synchronized 做了大量的优化,而且有多种锁状态,会从 【无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁】一步步转换。
AQS (Abstract Queued Synchronizer): 一个抽象的队列同步器,通过维护一个共享资源状态( Volatile Int State )和一个先进先出( FIFO )的线程等待队列来实现一个多线程访问共享资源的同步框架。
14.HashMap 为什么使用链表
减少和解决哈希冲突,把冲突的值放在同一链表下。
15.HashMap 为什么使用红黑树
当数据过多,链表遍历较慢,所以引入红黑树。
16.HashMap 为什么不一上来就使用红黑树
维护成本较大,红黑树在插入新的数据后,可能会进行【变色、左旋、右旋】来保持平衡,所以当数据少时,就不需要红黑树。
17. 说说你对红黑树的理解(❕❕需要扩展)
①根节点是黑色。
②节点是黑色或红色。
③叶子节点是黑色。
④红色节点的子节点都是黑色。
⑤从任意节点到其子节点的所有路径都包含相同数目的黑色节点。
红黑树从根到叶子节点的最长路径不会超过最短路径的 2 倍。保证了红黑树的高效。
18. 为什么链表长度大于 8,并且表的长度大于 64 的时候,链表会转换成红黑树?
因为链表长度越长,哈希冲突概率就越小,当链表等于 8 时,哈希冲突就非常低了,是千万分之一,我们的 map 也不会存那么多数据,如果真要存那么多数据,那就转为红黑树,提高查询和插入的效率。
19. 为什么转成红黑树是 8 呢?而重新转为链表阈值是 6 呢?
因为如果都是 8 的话,那么会频繁转换,会浪费资源。
20. 为什么负载因子是 0.75?(冲突和利用率)
加载因子越大,填满的元素越多,空间利用率越高,但发生冲突的机会变大了;
加载因子越小,填满的元素越少,冲突发生的机会减小,但空间浪费了更多了,而且还会提高扩容 rehash 操作的次数。
“冲突的机会”与 “空间利用率” 之间,寻找一种平衡与折中。
又因为根据泊松分布,当负载因子是 0.75 时,平均值是 0.5,带入可得,当链表为 8 时,哈希冲突发生概率就很低了。
21. 什么时候会扩容?
元素个数 > 数组长度 * 负载因子 例如 16 * 0.75 = 12, 当元素超过 12 个时就会扩容。
链表长度大于 8 并且表长小于 64,也会扩容
22. 为什么不是满了扩容?
因为元素越多,空间利用率是高了,但是发生哈希冲突的几率也增加了。
23. 扩容过程
- jdk1.7: 会生成一个新
table,重新计算每个节点放进新table,因为是头插法,在线程不安全的时候,可能会出现闭环和数据丢失。 - jdk1.8: 会生成一个新
table,新位置只需要看(e.hash & oldCap)结果是 0 还是 1;0 就放在旧下标,1 就是旧下标 + 旧数组长度。避免了对每个节点进行 hash 计算,大大提高了效率。e.hash 是数组的 hash 值,,oldCap 是旧数组的长度。
24.HashMap 和 Hashtable 的区别
| HashTable | HashMap |
|---|---|
| Key Value 不能 null | Key Value 可为 null |
| 线程安全 | 线程不安全 |
25. 集合为什么要用迭代器 (Iterator)
更加安全,因为它可以确保,在当前遍历的集合元素被更改的时候,就会抛出 ConcurrentModificationException 异常。
如果不用迭代器,只能 for 循环,还必须知道集合的数据结构,复用性不强。



